What The Agent Sees On Reset
Alert — no code, no traceback, just this:
"Training completed. Metrics look suspicious and vary between evaluation runs."
run_code
get_traceback
inspect_gradients
print_shapes
view_source
· 5 steps total
🎮 Live Demo — Try It
Step 1 — Reset (start a new episode)
Task:
Click "POST /reset" to start an episode...
Step 2 — Inspect (call a diagnostic tool)
Tool:
Reset first, then inspect...
Step 3 — Fix (submit your fix)
Bug type:
Inspect first, then submit fix...
📋 Try In Terminal
Reset — start episode on expert task
curl -s -X POST https://rak2315-ml-debug-env.hf.space/reset -H "Content-Type: application/json" -d "{\"task_id\": \"compound_leakage_eval\"}"
Inspect — call run_code tool
curl -s -X POST https://rak2315-ml-debug-env.hf.space/step -H "Content-Type: application/json" -d "{\"action\": {\"action_type\": \"inspect\", \"tool_name\": \"run_code\"}}"
Inspect — call inspect_gradients tool
curl -s -X POST https://rak2315-ml-debug-env.hf.space/step -H "Content-Type: application/json" -d "{\"action\": {\"action_type\": \"inspect\", \"tool_name\": \"inspect_gradients\"}}"
Fix — submit a fix attempt
curl -s -X POST https://rak2315-ml-debug-env.hf.space/step -H "Content-Type: application/json" -d "{\"action\": {\"action_type\": \"fix\", \"bug_type\": \"compound_leakage_eval\", \"diagnosis\": \"Two bugs: data normalized before split and model.eval() missing\", \"fixed_code\": \"# placeholder\"}}"
Health check
curl https://rak2315-ml-debug-env.hf.space/health
List all 8 tasks
curl https://rak2315-ml-debug-env.hf.space/tasks
📈 Training Results — GRPO on Qwen2.5-1.5B
Run 1 exposed grader bugs — fixed them. Run 2 showed improvement. The environment improved itself.
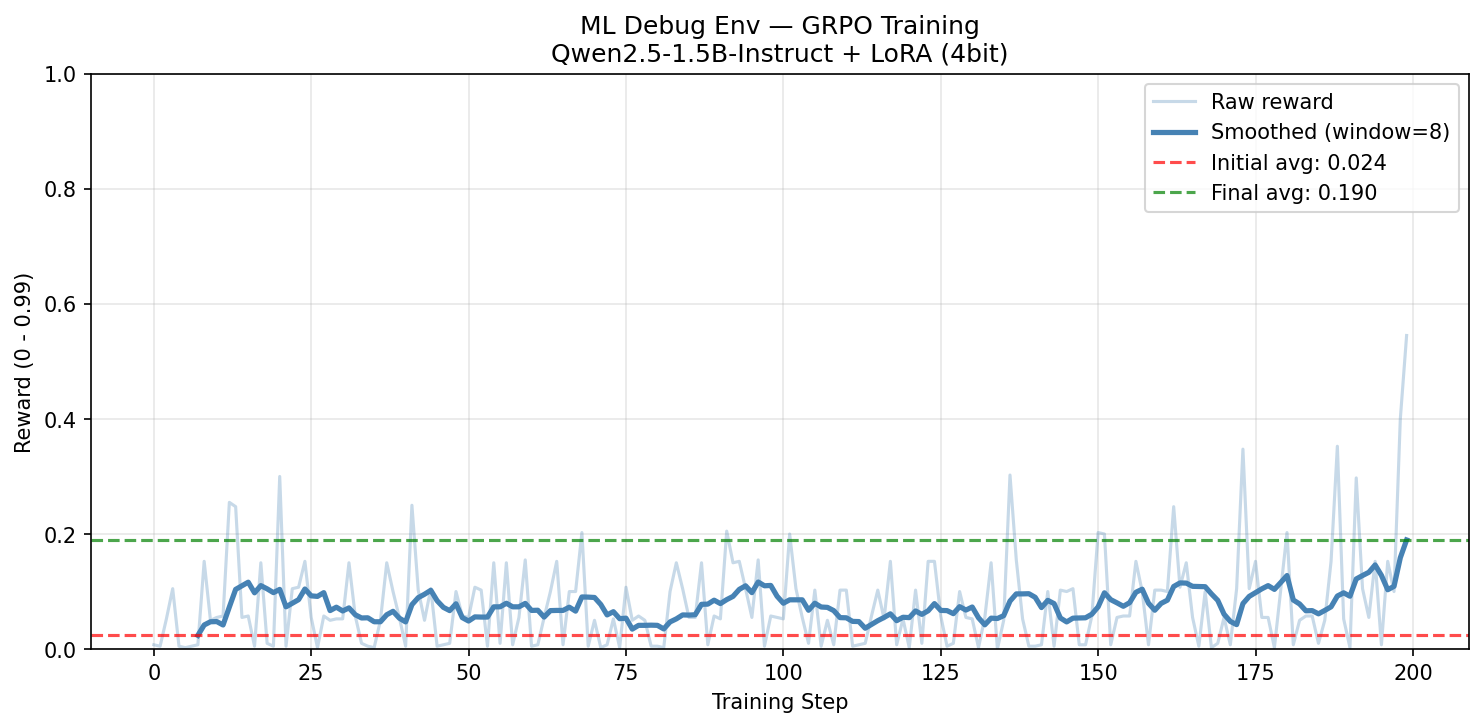
0.024
Initial reward
→
200 steps · T4
0.190
Final reward
+0.166
Improvement
🎯 8 Tasks — Easy to Expert
shape_mismatchEasy
nn.Linear input dim wrong → explicit RuntimeError crash on first forward pass.
training_collapseMedium
Bad LR → NaN loss, or wrong loss fn → flat plateau. No crash.
wrong_deviceMedium
Model on GPU, data on CPU → device mismatch crash on first forward pass.
gradient_not_zeroedMedium-Hard
Missing zero_grad() → gradients accumulate → loss explodes silently to NaN.
data_leakageHard
Normalized before split → 96% accuracy that can't be trusted. No crash.
missing_eval_modeHard
No model.eval() → Dropout active during eval → non-deterministic metrics.
compound_shape_deviceMedium-Hard
TWO bugs: shape mismatch + device mismatch. Both must be fixed for 0.99.
2 bugs
compound_leakage_evalExpert
TWO silent bugs: data leakage + missing eval mode. No crash. Frontier models score 0.
2 bugs
🏆 Scoring Ladder
0.01Wrong bug type identified
0.20Right type, fixed code crashes
0.40Code runs, training incomplete
0.60Training completes, root cause not fixed
0.80Root cause fixed, success signal missing
0.99Perfect fix ✅ + efficiency bonus ×1.2
🌐 API Endpoints
POST/resetStart episode — alert + tools only, no code
POST/stepinspect action (tool call) or fix action
GET/stateEpisode state, tools used, best score
GET/tasksAll 8 tasks with descriptions + action schema
POST/graderScore a fix directly without a full episode
GET/baselineRun built-in LLM agent on all 8 tasks
GET/health{"status": "healthy"}
GET/docsSwagger UI
WS/wsPersistent WebSocket session